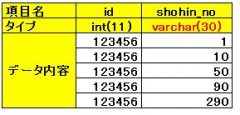
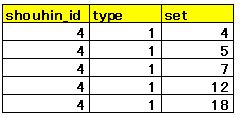
bigqueryのbqコマンドを利用したテーブルスキーム指定は現在2種類あります。
1)bq loadコマンド実行時にコマンド内に直書きする
bq load --skip_leading_rows=1 {DB名}.{テーブル名} ${HOME}/csv/{テーブルに入れるレコード}.csv ymd:date,allDAU:integer,event_joinUU:integer
2)bq loadコマンド実行時にjsonファイルからレイアウトを取得する
bq load --skip_leading_rows=1 {DB名}.{テーブル名} ${HOME}/csv/{テーブルに入れるレコード}.csv ${HOME}/json/scheme/{テーブルに設定する項目定義}.json
1)のやり方だと、テーブルレイアウト変更時や、環境移行対応時に手間がかかる可能性が高い為、2)の手法の方が安定的になります。
↓以下に上記で設定したcsvとjsonの例
# {テーブルに入れるレコード}.csvの例
ymd,allDAU,event_joinUU
2018-01-26,55000 ,36000
2018-01-27,55500 ,36200
2018-01-28,56000 ,37000
2018-01-29,56500 ,37100
2018-01-30,57000 ,37200
# {テーブルに設定する項目定義}.jsonの例
[
{"name": "ymd", "type": "DATE", "mode": "required"},
{"name": "allDAU", "type": "INTEGER", "mode": "required"},
{"name": "event_joinUU", "type": "INTEGER", "mode": "required"}
]
このデータを用意して、2)のコマンドを実行すればbigquery上でテーブルを作成して、レコードを挿入する事が出来ます。