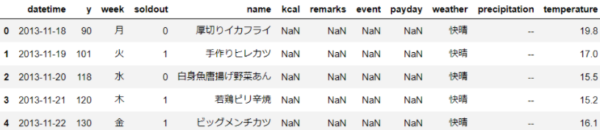
RMSEを最適化する場合のコード例
# optunaをインストール
!pip install optuna
# ライブラリをインポート
import optuna
import numpy as np
from sklearn.model_selection import train_test_split
from lightgbm import LGBMRegressor, early_stopping
from sklearn.metrics import mean_squared_error
# X(説明変数)とy(目的変数)は事前に準備しとく
train_X, val_X, train_y, val_y = train_test_split(X, y, test_size=0.2, random_state=42)
def objective(trial):
params = {
"n_estimators": trial.suggest_int("n_estimators", 100, 1000),
"learning_rate": trial.suggest_float("learning_rate", 0.01, 0.3, log=True),
"max_depth": trial.suggest_int("max_depth", 3, 15),
"num_leaves": trial.suggest_int("num_leaves", 31, 100),
"min_child_samples": trial.suggest_int("min_child_samples", 10, 50),
"subsample": trial.suggest_float("subsample", 0.5, 1.0),
"colsample_bytree": trial.suggest_float("colsample_bytree", 0.5, 1.0),
"reg_alpha": trial.suggest_float("reg_alpha", 0.0, 10.0),
"reg_lambda": trial.suggest_float("reg_lambda", 0.0, 10.0),
"random_state": 42, # 乱数のシードを固定
"verbose": -1 # トレーニング中の出力メッセージを非表示
}
model = LGBMRegressor(**params)
model.fit(train_X, train_y, eval_set=[(val_X, val_y)],
callbacks=[early_stopping(stopping_rounds=50, verbose=False)])
y_pred = model.predict(val_X)
rmse = np.sqrt(mean_squared_error(val_y, y_pred)) # RMSE
return rmse
study = optuna.create_study(direction="minimize")
study.optimize(objective, n_trials=100) # n_trials を増やすとより精度の高いチューニングが可能に
print("Number of finished trials:", len(study.trials))
print("Best trial:", study.best_trial.params)
print("Best value:", study.best_value)
▼出力例
~
Number of finished trials: 100
Best trial: {'n_estimators': 327, 'learning_rate': 0.12741920430017042, 'max_depth': 7, 'num_leaves': 52, 'min_child_samples': 21, 'subsample': 0.7130010142766848, 'colsample_bytree': 0.8733488672577971, 'reg_alpha': 2.2119815091261996, 'reg_lambda': 8.228991747822569}
Best value: 0.8479973555188078