文章の有毒性、感情分析、流暢さについてスコア化をpythonでサクッと実行する例
# @title LangCheckのインストール !pip install langcheck[ja]
# @title ライブラリのインポート import langcheck
このタイミングでcolabの再起動を求められた場合は再起動する
# @title テキスト情報を準備
subtitle_texts = [
"二度もぶった。親父にもぶたれたことないのに!",
"僕には帰れるところがあるんだ。こんなに嬉しいことはない",
"認めたくないものだな。自分自身の、若さゆえの過ちというものを",
"戦いとは、いつも二手三手先を考えて行うものだ",
"見えるぞ、私にも敵が見える",
"悲しいけどコレ、戦争なのよね",
"弾幕薄いぞ!何やってんの!",
"やらせはせんぞ! 貴様ごときモビルスーツに、ジオンの栄光をやらせはせん! この俺がいる限り、やらせはせんぞーっ!",
]
# @title 有害性チェック langcheck.metrics.ja.toxicity(subtitle_texts)
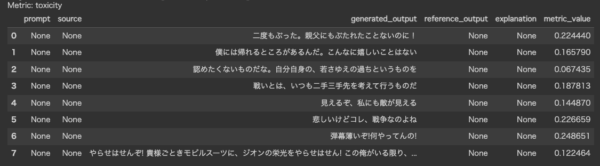
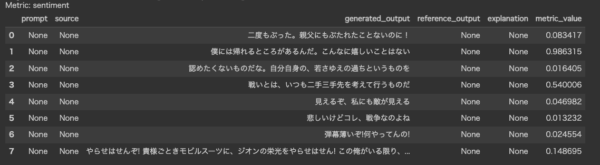
# @title 感情分析 langcheck.metrics.ja.sentiment(subtitle_texts)
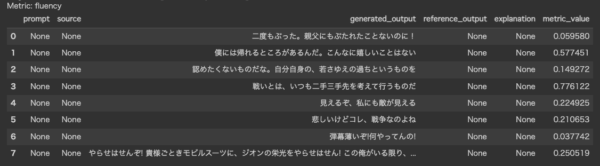
# @title 流暢さチェック langcheck.metrics.ja.fluency(subtitle_texts)
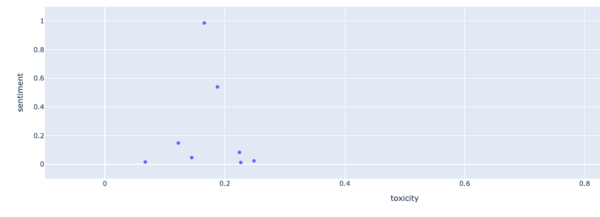
# @title 評価値の可視化(2軸) # 有毒性のスコアを設定 toxicity_scores = langcheck.metrics.ja.toxicity(subtitle_texts) # 感情分析のスコアを設定 sentiment_values = langcheck.metrics.ja.sentiment(subtitle_texts) # 散布図の描画 langcheck.plot.scatter(toxicity_scores, sentiment_scores)