はじめに
データエンジニアリングの世界でデファクトスタンダードとなっている dbt (data build tool)。 「試してみたいけれど、環境構築にお金をかけたくない」「実務に近い構成で学びたい」という方に向けて、Google BigQueryの無料枠を活用した最速のセットアップ手順をまとめました。
1. 全体構成
今回は以下の構成でハンズオンを行います。
- データ基盤: Google BigQuery(サンドボックス枠)
- 変換ツール: dbt-bigquery
- 実行環境: ローカルPC(Mac/Windows)
2. Google Cloud の事前準備
まずは、dbtが接続するための「箱(プロジェクト)」と「鍵(認証情報)」を用意します。
2.1 プロジェクトの作成
- Google Cloud Consoleにログイン。
- 新しいプロジェクトを作成します(例:
dbt-learning-project)。
2.2 サービスアカウントの発行
dbtがBigQueryを操作するための専用アカウントを作成します。
- 「IAMと管理」 > 「サービスアカウント」 へ移動。
- 「サービスアカウントを作成」 をクリック。
- ロールには 「BigQuery 管理者」 を選択してください。
- 作成後、詳細画面の 「キー」タブ から 「新しい鍵を作成(JSON)」 を選択し、ファイルをダウンロードします。
- ※このファイルは重要なので、
~/.gcp/などの安全なフォルダに保存しましょう。
- ※このファイルは重要なので、
3. dbt環境のセットアップ
次に、ローカルPC側の準備をします。
3.1 アダプターのインストール
dbt本体とBigQuery用のアダプターをインストールします。
pip install dbt-bigquery
3.2 プロジェクトの初期化
ターミナルで以下のコマンドを実行し、対話形式で設定を進めます。
dbt init my_dbt_project
【入力のポイント】
- Which database?:
bigqueryを選択 - Authentication method:
service_accountを選択 - Keyfile path: 先ほど保存したJSONファイルのパス(例:
/Users/name/.gcp/key.json) - Project ID: Google CloudのプロジェクトID
- Dataset:
dbt_workshop(dbtがテーブルを作成する場所の名前) - Threads:
1 - Location:
asia-northeast1(東京リージョンの場合)
4. 接続確認(dbt debug)
設定が正しいか、dbtがBigQueryに通信できるかを確認します。
cd my_dbt_project dbt debug
末尾に All checks passed! と表示されれば、あなたのPCとクラウドのデータ基盤が繋がった証拠です!
5. ハンズオン:最初のモデルを作ってみる
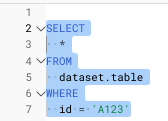
dbtの本質は、「SQLを書いて、データ間の依存関係を管理すること」にあります。
5.1 SQLを書く
models/my_first_model.sql を作成(または既存ファイルを編集)します。
{{ config(materialized='table') }}
with source_data as (
select 1 as id, '注文' as category, 100 as price
union all
select 2 as id, '属性' as category, 200 as price
)
select * from source_data
5.2 実行する
dbt run
このコマンドを打つだけで、BigQuery上に my_first_model というテーブルが自動生成されます。
6. まとめと次のステップ
この構成なら、どれだけ dbt run を繰り返しても、BigQueryの無料枠内であれば費用はかかりません。
次のステップとしておすすめ:
ref()関数の活用: 他のSQLを参照して、データの「家系図(リネージ)」を作る。- テストの実行:
schema.ymlを書いて、データに不備がないかdbt testで検証する。 - ドキュメント生成:
dbt docs generateで、自分だけのデータカタログをブラウザで見る。
おわりに
dbtを使うと、これまで複雑だったSQLの管理が驚くほどモダンになります。 エンジニアだけでなく、ビジネス側の人にも理解しやすい「透明性の高いデータ基盤」を目指して、ぜひ色々なモデルを作ってみてください!