↓jupyter notebookで、scikit-learnを使って機械学習する場合の手順は以下
# scikit-learnのインストール !pip install scikit-learn # 必要なライブラリの読み込み import matplotlib.pyplot as plt import pandas as pd import numpy as np import sklearn.datasets import sklearn.linear_model import sklearn.model_selection # scikit-learn に付属しているデータセットを読み込む(今回はBoston house-prices (ボストン市の住宅価格) boston = sklearn.datasets.load_boston()
※参考:scikit-learn に付属しているデータセットはこちら
# ボストン市の住宅価格のデータ内容を確認 df = pd.DataFrame(boston.data, columns = boston.feature_names) df.head(5) > CRIM ZN INDUS CHAS NOX RM AGE DIS RAD TAX PTRATIO B LSTAT 0 0.00632 18.0 2.31 0.0 0.538 6.575 65.2 4.0900 1.0 296.0 15.3 396.90 4.98 1 0.02731 0.0 7.07 0.0 0.469 6.421 78.9 4.9671 2.0 242.0 17.8 396.90 9.14 2 0.02729 0.0 7.07 0.0 0.469 7.185 61.1 4.9671 2.0 242.0 17.8 392.83 4.03 3 0.03237 0.0 2.18 0.0 0.458 6.998 45.8 6.0622 3.0 222.0 18.7 394.63 2.94 4 0.06905 0.0 2.18 0.0 0.458 7.147 54.2 6.0622 3.0 222.0 18.7 396.90 5.33
↓ 機械学習用(訓練用とテスト用)のデータを設定
# 住宅の変数(広さ等のデータ)をXに設定する
X = boston.data
# 住宅価格データをyに設定する
y = boston.target
y
>array([24. , 21.6, 34.7, 33.4, 36.2, 28.7, 22.9, 27.1, 16.5, 18.9, 15. ,
18.9, 21.7, 20.4, 18.2, 19.9, 23.1, 17.5, 20.2, 18.2, 13.6, 19.6,
15.2, 14.5, 15.6, 13.9, 16.6, 14.8, 18.4, 21. , 12.7, 14.5, 13.2,
13.1, 13.5, 18.9, 20. , 21. , 24.7, 30.8, 34.9, 26.6, 25.3, 24.7,
21.2, 19.3, 20. , 16.6, 14.4, 19.4, 19.7, 20.5, 25. , 23.4, 18.9,
35.4, 24.7, 31.6, 23.3, 19.6, 18.7, 16. , 22.2, 25. , 33. , 23.5,
~~ 長いので省略
# 交差検証:テストデータ(0.2)と訓練データ(0.8)をわける
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(X, y, test_size=0.2)
# 線形回帰(LinearRegression)のアルゴリズムを呼び出す
lr = sklearn.linear_model.LinearRegression()
# 機械学習をさせる
lr.fit(X_train, y_train)
> LinearRegression()
# 精度の検証
lr.score(X_test, y_test)
> 0.6937958951932385
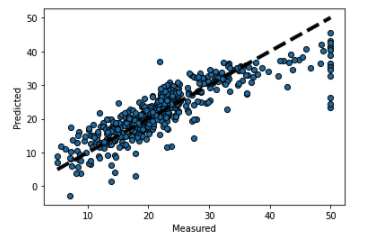
# 予測結果をmatplotlibで可視化する
fig, ax = plt.subplots()
ax.scatter(y, predicted, edgecolors=(0, 0, 0))
ax.plot([y.min(), y.max()], [y.min(), y.max()], 'k--', lw=4)
ax.set_xlabel('Measured')
ax.set_ylabel('Predicted')
plt.show()