1. はじめに
モダンなデータスタックとして定番の dbt。Redshift環境に導入した際、多くのエンジニアが最初に直面するのが Database Error: permission denied というエラーです。
「接続設定は合っているし、SELECTもできる。なのになぜ dbt run でコケるのか?」
今回は、初期導入段階で直面したこの課題の正体と、その解決策について解説します。
2. なぜRedshiftだけが「複雑」なのか
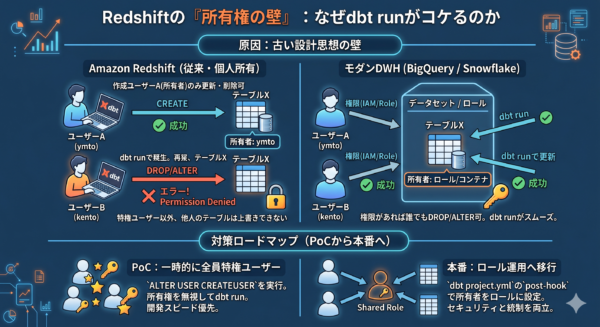
BigQueryやSnowflakeを触ったことがある人ほど、Redshiftの権限管理には戸惑うかもしれません。その理由は、Redshift(PostgreSQLベース)が持つ 「オブジェクト所有権(Ownership)」 という概念にあります。
モダンDWH(BQ/Snowflake)との違い
- BigQuery: IAMでデータセットの編集権限があれば、誰でもテーブルを更新・削除できます。
- Redshift: 「作った人が最強」 という古いUnix的な設計です。一度「ユーザーA」が作ったテーブルは、同じグループの「ユーザーB」であっても、削除したり上書きしたりすることは(たとえ管理者権限を持っていても!)原則できません。
dbtは内部的に DROP TABLE や CREATE TABLE AS... を行うため、この「他人の所有権」が壁となり、開発チーム内でバトンタッチした瞬間にエラーが多発するのです。
3. 直面したエラーの正体
今回、silver レイヤーから gold レイヤーへ処理を繋ごうとした際、以下の事象が発生しました。
- 現象:
dbt run実行時、特定のモデルでpermission deniedが発生。 - 原因: そのテーブルは過去に別のメンバーが作成したものだった。
- 厄介な点:
SELECTはできるため、依存先の入力データとしては使えるが、dbt run(上書き)だけが失敗する。
4. 解決策:PoCと本番で使い分ける戦略
この「所有権の壁」を突破するには、フェーズに合わせた2つのアプローチがあります。
アプローチA:PoCフェーズ(スピード優先)
対策:開発メンバー全員に CREATEUSER (スーパーユーザー) 権限を付与する。
ALTER USER your_user_name CREATEUSER;
- メリット: 所有権の壁を無視して誰でも上書き・削除が可能。権限待ちによる開発ストップを防げる。
- 注意点: 破壊的な操作も可能になるため、信頼できる少人数のチーム向け。
アプローチB:本番フェーズ(統制優先)
対策:共有ロールの作成 + dbtの post-hook で所有権を統一する。
dbtがテーブルを作成するたびに、所有者を個人から「共有ロール」へ自動変更する仕組みを組み込みます。
# dbt_project.yml
models:
+post-hook:
- "ALTER TABLE {{ this }} OWNER TO dbt_developer_role"
- メリット: セキュリティを担保しつつ、チーム開発を維持できる。
5. まとめ
Redshiftでdbtを運用する場合、「AWSの権限(IAM)」と「DB内部の権限(SQL)」は別物として考える必要があります。
特に初期開発時は、この「二重管理」の複雑さにハマりがちです。まずは CREATEUSER で詰まりを解消し、プロジェクトが成熟するにつれて post-hook によるロール運用へ移行していくのが、エンジニアにとって最もストレスの少ない「登竜門」の超え方ではないでしょうか。