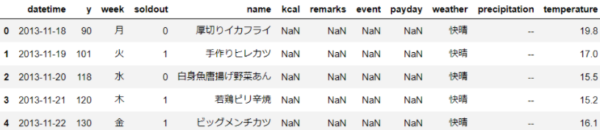
分析用に収集したデータに欠損値(null)が入っている場合、そのまま利用すると、正しい分析結果が得られない場合がある。
その為、この欠損値が含まれるデータを除外したり、欠損値を0や対象項目の平均値に変換して対処する事が多い。
以下は、データの読み込み~欠損値の対応例
# ライブラリの読み込み(numpyとpandas)
import numpy as np
import pandas as pd
# pandasを利用したデータの読み込み
df = pd.read_csv("xxxx.csv") -- 自分で用意したデータを利用
# データの確認
df.head()
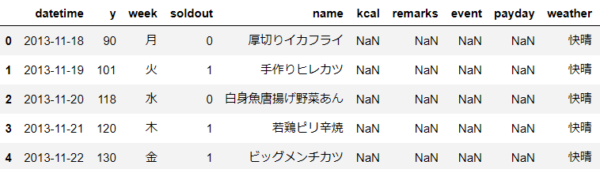
# 欠損値の有無の確認 > isnull関数を利用 df.isnull()
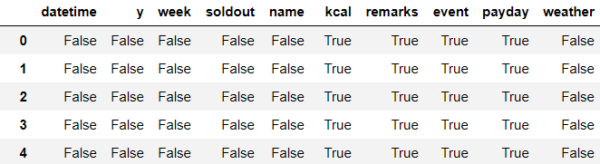
# 欠損値の存在有無の確認 > any関数を利用 df.isnull().any()

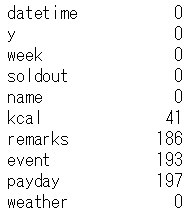
# 欠損値数の集計 > sum関数を利用 df.isnull().sum()
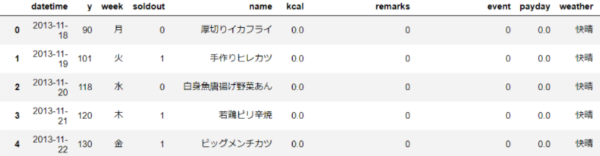
# 欠損値を0に変換する > fillna関数を利用して0を設定する df.fillna(0)
# 指定項目に欠損値があるデータを削除する > dropna関数で項目を指定する *以下ではkcalに欠損値が含まれるデータを除外する df.dropna(subset=["kcal"])
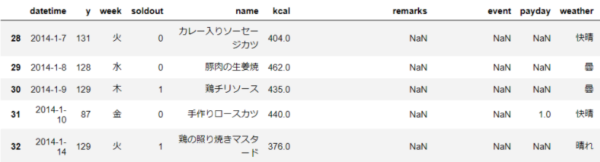
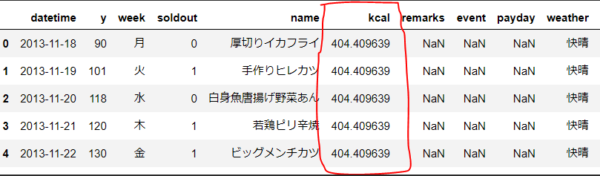
### 欠損値を対象項目の平均値に変換する方法 # 1)対象項目(ここでは"kcal"を利用)の平均値を算出してavgへ設定する > mean関数を利用 avg = df["kcal"].mean() # 2)kcal項目の欠損値に平均値を入れる > fillna関数を利用 df["kcal"] = df["kcal"].fillna(avg) # 3)testデータの中身を確認 > kcal項目の欠損値が平均値に代わっている df.head()