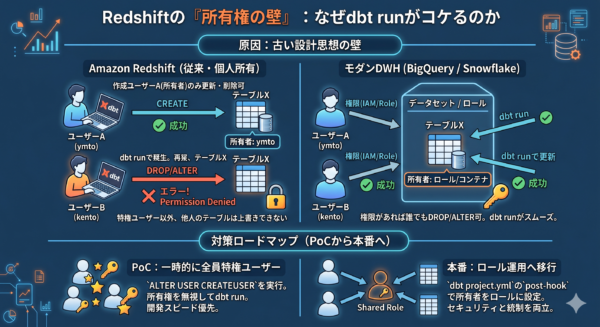
はじめに
dbt(Data Build Tool)を活用したデータマネジメントにおいて、データウェアハウス(DWH)内に構築するモデルの数が増えてくると、SQLの書き方(インデントのズレ、大文字・小文字の混在、カンマの位置など)が開発者ごとにバラバラになりがちです。
本記事では、SQLの静的解析・自動修正ツールである SQLFluff を用いて、ローカル環境を汚さずに既存のSQLを一括クリーンアップし、さらにAWS(CodeBuild / EventBridge)と連携して「ルールを満たした綺麗なコードしかマージさせない」自動化ライン(CI)を構築する手順をまとめます。
1. ローカル環境の美しさを保つ「仮想環境(venv)」のセットアップ
Mac(M4 Mac等の最新環境など)のグローバルなPython環境を汚さないために、プロジェクトごとに隔離された仮想環境(venv)を構築してツール一式をインストールします。
1-1. 仮想環境の作成とアクティベート
dbtプロジェクトのルートディレクトリで以下のコマンドを実行します。
# 1. 仮想環境(.venv)を作成 python3 -m venv .venv # 2. 仮想環境をアクティベート(有効化) source .venv/bin/activate
※有効化されると、ターミナルの先頭に (.venv) と表示されます。
1-2. バージョンを指定してインストール
実務運用の安定版として定評のあるバージョンを指定して、Linterとdbtアダプターをインストールします。
pip install --upgrade pip pip install sqlfluff==4.1.0 sqlfluff-templater-dbt dbt-redshift==1.8.1
1-3. Git管理の注意点(.gitignore)
インストールしたライブラリ群(.venv 内のファイル)はGitの追跡対象から外す必要があります。プロジェクト直下の .gitignore の末尾に以下を忘れずに追記します。
kpi_dbt/.venv/
2. 採点基準を決める設定ファイル(.sqlfluff)の配置
プロジェクトのルートに .sqlfluff という設定ファイルを配置し、チーム共通のSQLコーディング規約を定義します。
[sqlfluff] # 使用するDWHの種類を指定 dialect = redshift # dbtのJinja構文(refなど)を解釈するための設定 templater = dbt exclude_rules = None [sqlfluff:templater:dbt] # dbtプロジェクトのルートディレクトリを指定 project_dir = . # dbtがコンパイル時に必須とする profiles.yml の検索先をカレントディレクトリに指定 profiles_dir = . [sqlfluff:indentation] tab_width = 4 indented_ctes = True [sqlfluff:rules:aliasing.table] aliasing = explicit # テーブルエイリアスの際に AS を必須にする [sqlfluff:rules:aliasing.column] aliasing = explicit # カラムエイリアスの際に AS を必須にする [sqlfluff:rules:capitalisation.keywords] capitalisation_policy = upper # SQLキーワード(SELECTなど)は大文字に統一 [sqlfluff:rules:capitalisation.identifiers] capitalisation_policy = lower # カラム名などの識別子は小文字に統一 [sqlfluff:rules:layout.commas] line_position = trailing # カンマの配置場所を末尾(trailing)に固定
3. ローカルでの実行と一括「大掃除」のやり方
環境が整ったら、既存のSQLファイル(数十〜数百本規模)の検証と自動修正を行います。
3-1. 構文チェック(lint)
sqlfluff lint models/
models/フォルダ配下の全SQLファイルが対象。- ルール違反がある場合、「行番号(L)」「文字位置(P)」「ルールID(CP01等)」 と共に具体的な警告内容が一覧表示されます。
3-2. 自動一括修正(fix)
手動で1つずつ直す必要はありません。以下のコマンドを実行することで、インデントや大文字化、カンマ位置などが数秒で自動修正されます。
sqlfluff fix models/ # 「Really fix all errors? [y/n]」と聞かれるので「y」を入力してエンター
修正後、再度 sqlfluff lint models/ を実行し、All linter checks passed! と表示されればクリーンアップ成功です。
4. AWS(CodeBuild / EventBridge)によるCI自動化の構築
「マージされる前(プルリクエスト時)」にロボットが自動でこのチェックを走らせる防衛網を構築します。
4-1. CI環境の網の目をくぐり抜ける「ダミー接続書(ci_profiles.yml)」の作成
SQLFluffをdbtモードで動かす場合、内部で dbt compile が走るため、接続設定(profiles.yml)が絶対に必要になります。 しかし、CI環境から本物のDWHに接続する必要はなく(文字列のチェックのみであるため)、またGitにパスワードを載せるわけにはいかないため、プロジェクト内に以下の ci_profiles.yml を配置します。
# CI用のダミープロファイル(SQLFluffの構文パースを通すためだけのもの)
# ⚠️注意:一番上のプロファイル名は dbt_project.yml の profile 指定と完全に一致させること
kpi_dbt_redshift:
outputs:
dev:
type: redshift
host: dummy-host
user: dummy-user
password: dummy-password
port: 5439
dbname: dummy-db
schema: public
target: dev
4-2. CI環境の指示書(buildspec.yml)の書き方
CodeBuildのコンテナ内で、一時的にこのダミーファイルをdbtが認識できる名前(profiles.yml)にコピーして実行させる手順を記述します。これにより、ローカル環境を破壊せず、CIコンテナ内だけで安全にパースを通過させます。
version: 0.2
phases:
install:
runtime-versions:
python: 3.9
commands:
- echo "Installing SQLFluff and dbt-redshift..."
- pip install dbt-redshift==1.8.1 sqlfluff-templater-dbt
pre_build:
commands:
- echo "Checking versions and initializing dbt..."
- sqlfluff --version
- dbt --version
- cd $CODEBUILD_SRC_DIR/kpi_dbt
- dbt deps
build:
commands:
- echo "Running SQLFluff Lint..."
- cd $CODEBUILD_SRC_DIR/kpi_dbt
# 使い捨てコンテナのデフォルトディレクトリにダミープロファイルを配置
- mkdir -p ~/.dbt
- cp ci_profiles.yml ~/.dbt/profiles.yml
- sqlfluff lint models/
5. 【コスト最適化】無駄な起動を抑える EventBridge のフィルター設定
「READMEを直しただけ」「画像を足しただけ」の時に毎回CodeBuildがフル稼働すると、インフラコストが無駄になってしまいます。 Amazon EventBridge の [イベントパターン (フィルター)] を以下のように最適化することで、「.sql や .yml などの重要ファイルが変更された時だけ」 スイッチがONになるエコな設計が実現します。
5-1. イベントパターン (フィルター) のJSON
{
"source": ["aws.codecommit"],
"detail-type": ["CodeCommit Pull Request State Change"],
"detail": {
"event": ["pullRequestCreated", "pullRequestSourceBranchUpdated"],
"destinationReference": ["refs/heads/main"],
"changedFiles": {
"absolutePath": [
{"suffix": ".sql"},
{"suffix": ".yml"},
{"suffix": ".yaml"}
]
}
}
}
5-2. 確実にPRのブランチをテストするための「入力トランスフォーマー」
EventBridgeからCodeBuildへ「現在ターゲットとなっているPRのブランチ名」を正確に伝言するために、ターゲットの追加設定から 入力トランスフォーマー を有効化し、以下を設定します。
- 入力パス:JSON
{"sourceReference": "$.detail.sourceReference"} - テンプレート:JSON
{"sourceVersion": "<sourceReference>"}
まとめ
ここまでの設定が完了すると、開発の流れは次のように進化します。
- ローカルで開発者が
venv環境に入り、sqlfluff fixでコードを綺麗にする。 - CodeCommitでプルリクエストを作成する。
.sqlなどの変更を検知して EventBridge が起動。- 正しいPRブランチ名を作業員(CodeBuild)に伝言。
- コンテナ内でダミープロファイルを元に
sqlfluff lintが自動実行され、合格したものだけがmainブランチへのマージを許される。
この仕組みを導入することで、不毛な「インデントの修正依頼」のようなコードレビューコストがゼロになり、データエンジニアはビジネスロジックが正しいかどうかの本質的なレビューに100%集中できるようになります。
ブログ記事の構成として、全体の流れ、技術的な重要ポイント、そして何より「なぜそのダミーや設定が必要なのか」という意図がいつでも思い出せるよう整理しました。
この記録をベースに、今後の運用やデータプラットフォームのさらなる拡張にお役立てください!